

To address the long standing conundrum of how to easily collect repeating data in a meaningful way using systematic review software, we developed the Hierarchical Data Extraction (HDE) method in 2017. Although this method is a significant improvement over any previous approaches to collecting hierarchical repeating data, it requires users to navigate between multiple forms, each one capturing a different repeating data set.
So we set out to make hierarchical data extraction even easier and, through iterative work with the user community, came up with HDE Tables, which allow all repeating data to be collected in a single form while still achieving all of the benefits of the original HDE solution.
To help illustrate the uses for this new format, we will use the following case study to compare the two options of data collection.
The Case – Repeating Data Sets
Let’s say you want to collect data from a study that has a baseline measurement, a measurement at 1 week after the intervention, and again at 6 weeks post-intervention. There is a control group and two different intervention groups, and the study is examining two possible outcomes: changes to participant Body Mass Index and Cholesterol. You want to be able to associate each set of data from each time point to the appropriate intervention group and measurable outcome. Each type of repeating data would need to be collected using a distinct form:
- Parent Form (1) – Outcomes Measured
- Child Form (2) – Intervention Groups
- Grand Child Form (3) – Time Point Measurements
Because each of these data sets have multiple instances and they relate to one another (the time point measurement relates to a specific intervention group, which relates to a specific outcome being measured), these forms must collect data in a way that maintains these hierarchical relationships.
The relationships between the datasets you collect from this study would look like this:
- Study Characteristics (Non-Repeating)
- Intervention: Control
- Timepoint: Baseline
- Timepoint: 1 week after intervention
- Timepoint: 6 weeks after intervention
- Intervention: Medication
- Timepoint: Baseline
- Timepoint: 1 week after intervention
- Timepoint: 6 weeks after intervention
- Intervention: Exercise
- Timepoint: Baseline
- Timepoint: 1 week after intervention
- Timepoint: 6 weeks after intervention
- Intervention: Control
- Timepoint: Baseline
- Timepoint: 1 week after intervention
- Timepoint: 6 weeks after intervention
- Intervention: Medication
- Timepoint: Baseline
- Timepoint: 1 week after intervention
- Timepoint: 6 weeks after intervention
- Intervention: Exercise
- Timepoint: Baseline
- Timepoint: 1 week after intervention
- Timepoint: 6 weeks after intervention
- Outcome: Cholesterol
- Outcome: BMI
So, for each grandchild form, you end up collecting the following sets of data:
- Baseline measurement for the control intervention group for the cholesterol outcome
- 1 week measurement for the control intervention group for the cholesterol outcome
- 6 week measurement for the control intervention group for the cholesterol outcome
And so on, repeating for each time point, intervention group, and outcome measured.
Hierarchical Data Extraction (HDE)
Using the original HDE method, the child forms relate to the parent forms via the hierarchical relationship established in your DistillerSR level settings, with each repeating data set having its own unique form. Key questions are used to uniquely identify and connect each instance of a parent form to its child forms in a coherent way. Navigating between each of the forms is done through tabs or through a visually hierarchical data navigation tree.
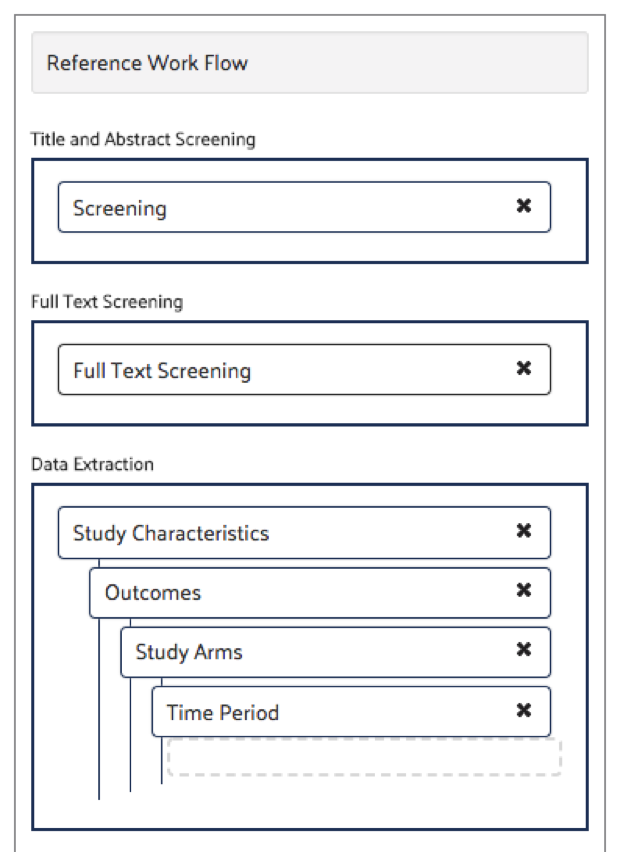
The relationship is clear because of the parent child-relationships established in the hierarchical setup.
HDE Tables (Subforms)
Using HDE Tables, the setup is different. All of the data collection will occur within one form, and your DistillerSR level settings are not used to establish a hierarchical relationship. Instead, HDE Tables use subform tables to collect data for each level of the hierarchy.
When creating the HDE Tables, you create or use the same forms that you would with traditional HDE (Outcomes and Interventions). These forms are embedded within the overall parent form. As the reviewer creates new repeating forms to capture repeating data, each “form” is represented as a row in a table.
When different, hierarchically related, repeating forms are embedded in a parent form, the reviewer must explicitly link parent and child form by recording the key of each parent in the child form.
HDE vs HDE Table
- Study Characteristics (Non-Repeating)
- Intervention: Control
- Timepoint: Baseline
- Timepoint: 1 week after intervention
- Timepoint: 6 weeks after intervention
- Outcome: Cholesterol
- Cholesterol – Control – Baseline
- Cholesterol – Control – 1 Week
- Cholesterol – Control – 6 Weeks
All of your multiple submission forms are embedded into one overall form using the Table (Subform) question type. This overall form can be used to collect single submission data such as your study characteristics as well as a way to combine the repeating forms.
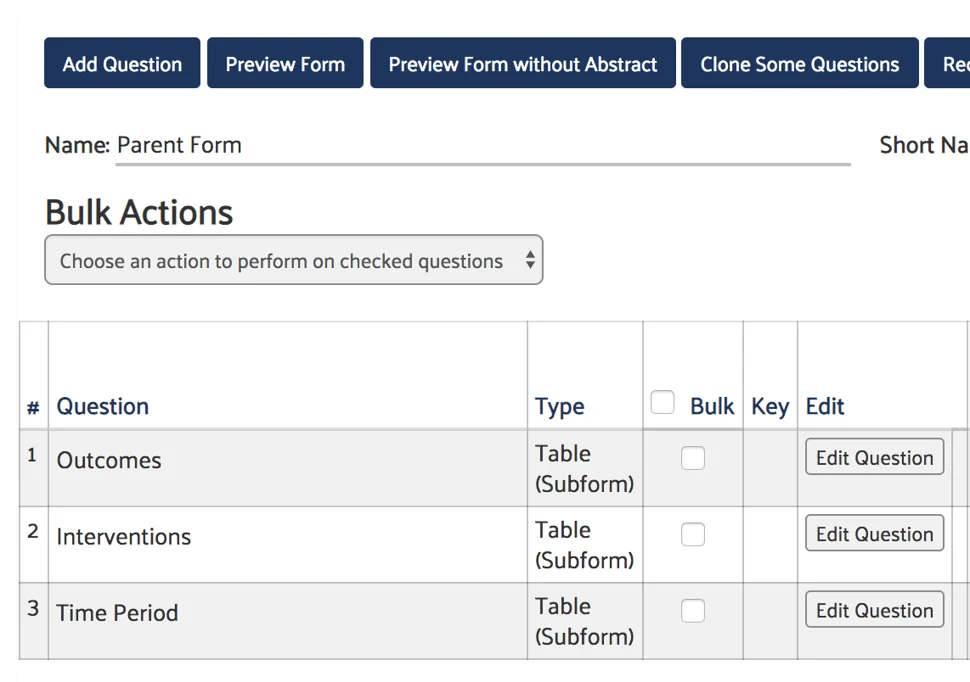
Using HDE Tables, data is captured the same way as with HDE, the main difference being that each row in the subform table equates to an individual form in the traditional HDE method and, as stated above, the reviewer has to manually join parents and children using keys. This allows you to perform data extraction and review the results in a single page, rather than multiple tabs/forms.
For a complete guide on how to set up HDE or HDE Tables, please see the Hierarchical Data Extraction section in the DistillerSR User Guide.




